Module 18 — Introduction to PyTorch¶
18.1 The Unifying Theme ⬤ ¶
We have discussed various different models. While there are significant differences, a unifying theme has emerged:
- Each model has a forward function, that takes an input point and evaluates it into a prediction.
- The forward function depends on the inputs, but also on a set of trainable parameters.
- The goal is to train the parameters so that the predicted outputs are 'close' to the desired outputs.
- This 'closeness' is captured mathematically by a loss function.
- Training is done by using an external optimizer.
- The optimizer utilizes gradients of the loss function.
This unifying theme provides a general framework that can be potentially very powerful:
18.1.1 Degrees of Flexibility¶
18.1.1.1 Forward Functions and Custom Layers¶
So far we have discussed neural network models that have relatively straightforward forward functions consisting of hidden layers with identical non-linear activations. But, in principle, we can imagine hidden layers of mixed types with other activation functions. Or we can imagine even more complicated forward functions, as illustrated on the right side of this picture.
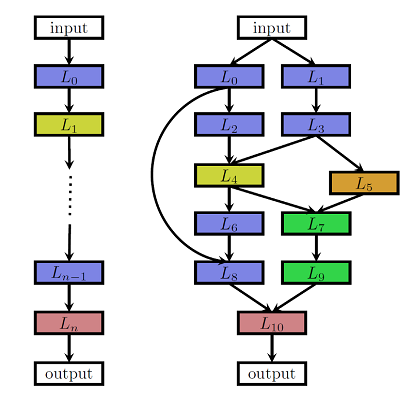
In general the forward computation can be any program that computes a function, and such a function can be represented always as a diagram like the ones above, also known as computation graphs. Notice that these graphs have directed arcs that indicate the flow/order of the computation, and that they do not contain any cycles.
18.1.1.2 Loss Functions¶
We have discussed a number of loss functions, and their regularized counterparts, but many alternatives exist or can be conceived.
18.1.1.3 Optimizers¶
There are also many different optimizers one can use, even custom-made optimizers.
18.1.2 PyTorch¶

In a nutshell, PyTorch provides all the 'degrees of flexibility' we discussed above. It provides multiple pre-programmed types of network layers, forward functions, loss functions and optimizers, but it is also fully customizable: one can implement (in Python syntax) almost any imaginable model. In fact it makes research and discovery much simpler and available to everyone: if tomorrow you come up with an idea on a new non-linear activation function, you can implement it in a few lines of code. And if the idea is good in practice, it has the potential to change the course of ML and Deep Learning and have a huge impact in practice!
PyTorch is essentially a programming language built on top of Python (as a module), and it is an open source effort started in Facebook (the company). Tensorflow is a similar effort by Google, that actually preceded PyTorch. They are both quite popular, although currently (in 2023) PyTorch seems to have the upper hand among researchers.
18.1.3 Automatic Differentiation¶
PyTorch can provide all these degrees of flexibility for various technical reasons, including importantly the implementation of automatic differentiation: PyTorch can evaluate (in training mode) a batch of points, and then automatically compute all the derivatives that are needed for updating the weights. The computation of these derivatives is fast, and the time required for the gradient computation is in the same order of magnitude as the forward computation.
18.1.4 GPU Computations¶
An additional important feature of PyTorch is its ability to utilize Graphics Processing Units (GPUs). GPUs were originally developed to support fast graphics, which rely on very special operations like matrix multiplications that can leverage the availability of the multiple cores that are available in GPUs. GPUs have also a very special memory organization, specializing in handling arrays of data. So they have more potential for parallelism and faster memory relative to multicore CPUs, making them many times faster relative to CPUs for some types of operations. Here is a comparison of a CPU and a GPU from the same year.
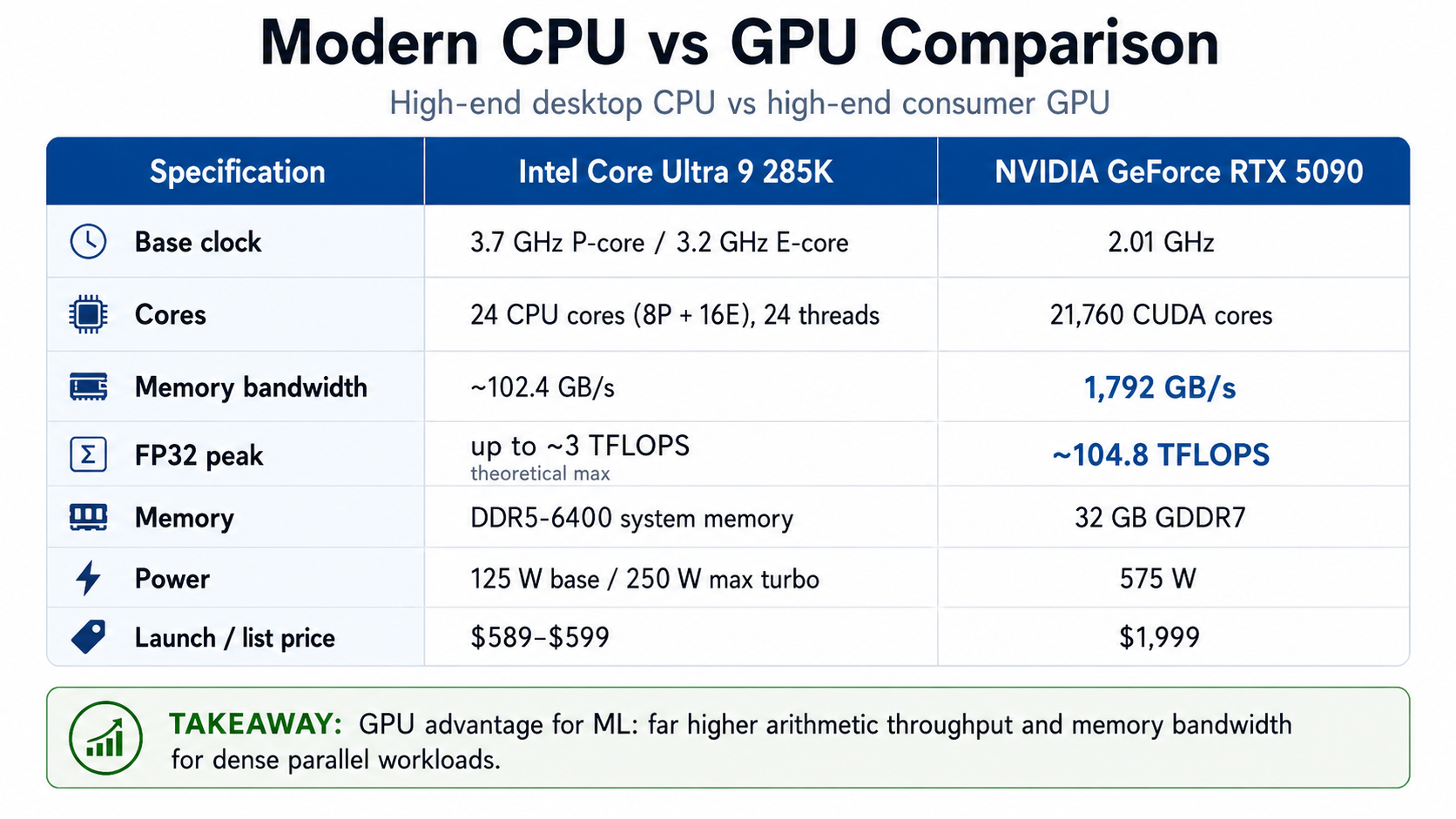
GPUs are fast in precisely the types of computational operations that are used in neural networks, and so they are ideal for neural networks.
PyTorch also provides mechanisms for handling big data that does not fit in memory. The combination of the availability of GPUs along with big datasets is what enabled the enormous progress in ML and Deep Learning after the year 2010. The basic ingredients had already been known and studied since at least 20 years earlier, but GPUs and data is what rendered them practical and successful. Of course, the availability of PyTorch and Tensorflow further sped up innovation and research into various types of neural network architectures.
18.2 A Regression Example with PyTorch ⬤ ¶
This notebook demonstrates a simple use of PyTorch on a small regression problem on a random dataset. The notebook illustrates what we discussed earlier about Universal Approximation Theorems: neural networks are quite effective in 'memorizing' data.
Remark: One important thing to notice in these notebooks is that all objects used (including the dataset) are torch objects. Unlike scikit-learn that can work with numpy objects, PyTorch requires tensor objects that have appropriate properties for supporting automatic differentiation.