Module 9 — Hyperparameter Tuning and Validation¶
9.1 Validation Sets ⬤ ¶
We have already discussed that we commonly split the dataset $X$ into training and test datasets $X_{\mathit{train}}$ and $X_{\mathit{test}}$. We train a model on $X_{\mathit{train}}$, and then use $X_{\mathit{test}}$ to get an estimate of how the model will perform on new unseen points. In that sense, $X_{\mathit{test}}$ can help us counteract overfitting on $X_{\mathit{train}}$.
But even before we train the model, we have to decide what type of algorithm to use and then set a number of hyperparameters. Consider as a simple example the $k$-NN algorithm, where we must select a value of $k$, and also the type of distance to use. Suppose we want to try $20$ different values for $k$ and two different types of distances. That means there are 40 different combinations of settings for the hyperparameters, and we want to determine which combination is best. One simple idea is to train $40$ different models on $X_{\mathit{train}}$, then check their accuracy on the test set, and finally select the model with the best performance.
However, if we do check all 40 combinations of settings, then due to the large number of experiments, there is a chance that the performance of the best model on the test set may be the result of some random overfitting to the test set. This type of overfitting is not the same as the training overfitting, which is expected and systematic — in checking 40 combinations of settings, the model itself is selected so as fit $X_{\mathit{train}}$. However, such random overfitting can happen, and if it happens, our estimate of the model's real performance will not be accurate. So, if we 'deploy' such a model in a product, the product will turn out to have a subpar performance.
For that reason, we often split the set $X$ into three sets: $X_{\mathit{train}}$, $X_{\mathit{valid}}$ and $X_{\mathit{test}}$. The validation set $X_{\mathit{valid}}$ is used exactly like a test set in the above discussion: We use validation to select the best setting of the hyperparameters.
In practice, training accuracy/score is usually higher than both validation and test scores due to overfitting. But we also sometimes see that the validation score will be higher than the test score, which means that we do get some accidental overfitting on the validation set. However the gap between validation and test scores is usually relatively small, and the test score usually provides a reasonable estimate of the real performance of the model.
In general, when we select among a number of models, we should always pick the one with the highest validation score. And it is good practice to avoid looking at the test set until the very end of the model design process.
9.2 Validation for Picking the Best Model over Multiple Epochs ⬤ ¶
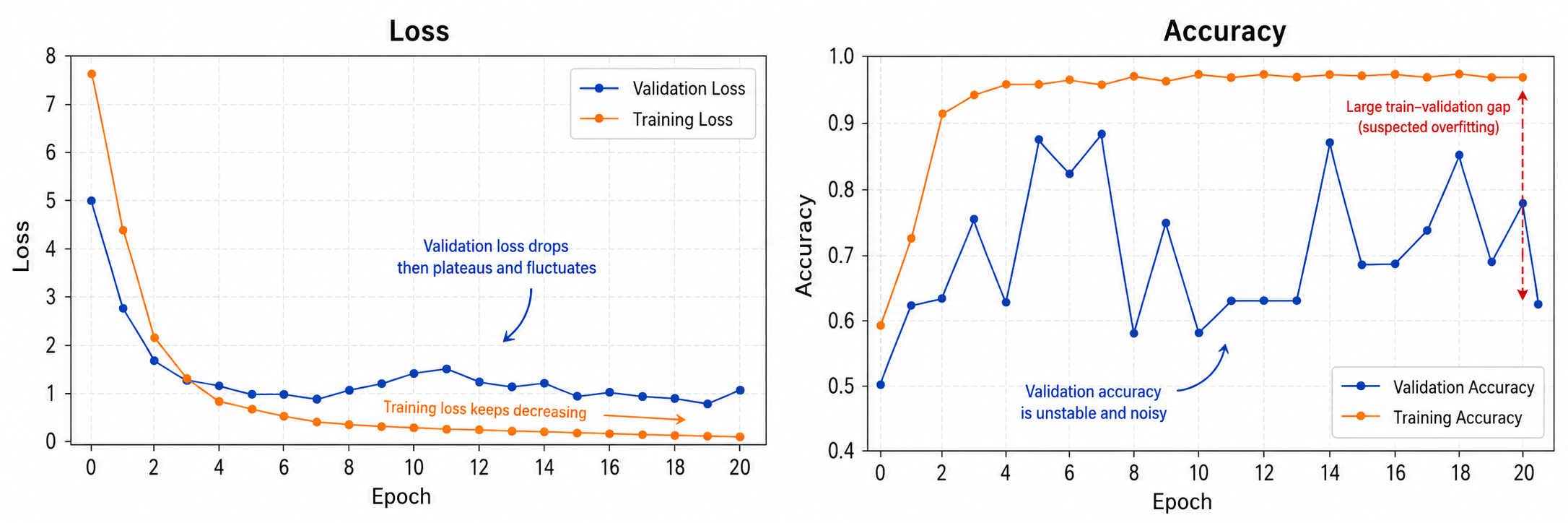
A common way of using validation sets is to detect overfitting during the training of more complex models that we will discuss in later chapters.
We often see the training loss decreasing over many epochs, but the validation loss (the value of the loss function on $X_{\mathit{valid}}$) stops decreasing, and may start to increase. Conversely, the training accuracy may keep increasing, but validation accuracy may not follow. So, another use of the validation set is to detect the epoch where the validation score reached its higher value (or began to decline), and use the model from that epoch.
9.3 k-Fold Validation ⬤ ¶
The use of a validation set means that we will have fewer points with which to train and test. Of course training data points are very valuable, especially in applications with small datasets. In order to avoid such 'waste' of training data, but also to get a possibly more reliable estimate for real performance, we use a process known as $k$-fold validation.
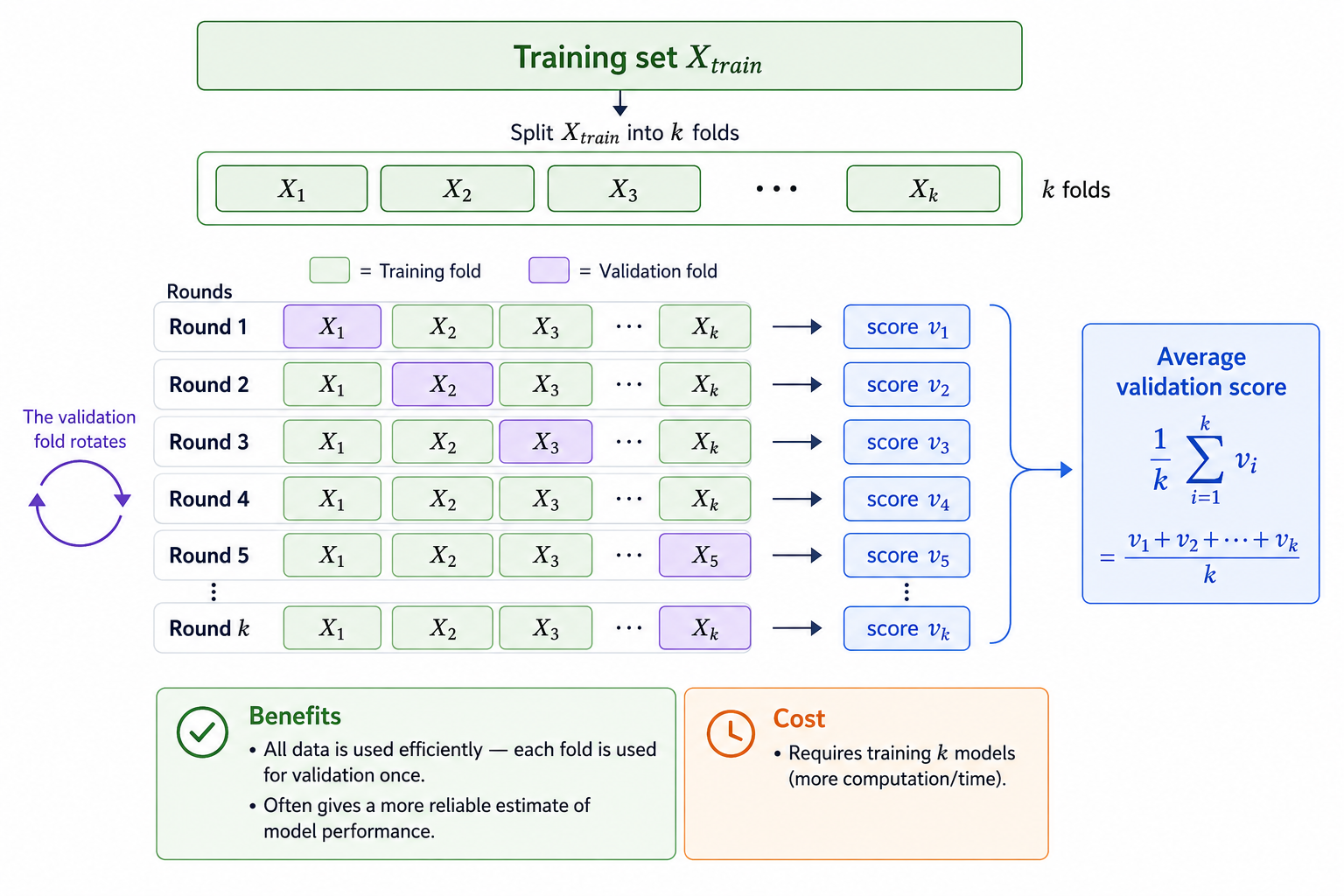
In $k$-fold validation (where $k$ is a hyperparameter usually set to small values like 3, 5 or 10), we have a single training set $X_{\mathit{train}}$ that we split into $k$ 'folds', $X_{1},\ldots,X_{k}$. We then train $k$ different models where for the $i^{th}$ model, we use as a validation set fold $X_i$ and as a training set all folds except $X_i$. Then for each of these $k$ models we get a different validation score $v_i$, and we return as an overall validation score the average, $\frac{1}{k}\sum_{j=1}^k v_i$ .
One drawback of $k$-fold validation is that it requires more training time, as $k$ different models must be trained.
9.4 Grid Search Notebook ⬤ ¶
Scikit-learn provides functionality that automates model selection after hyperparameter tuning. The 'grid search' approach trains and ($k$-fold) validates one model for each hyperparameter setting in a list of settings provided by the user. It then returns the model with the highest validation score.
Here is the code notebook.